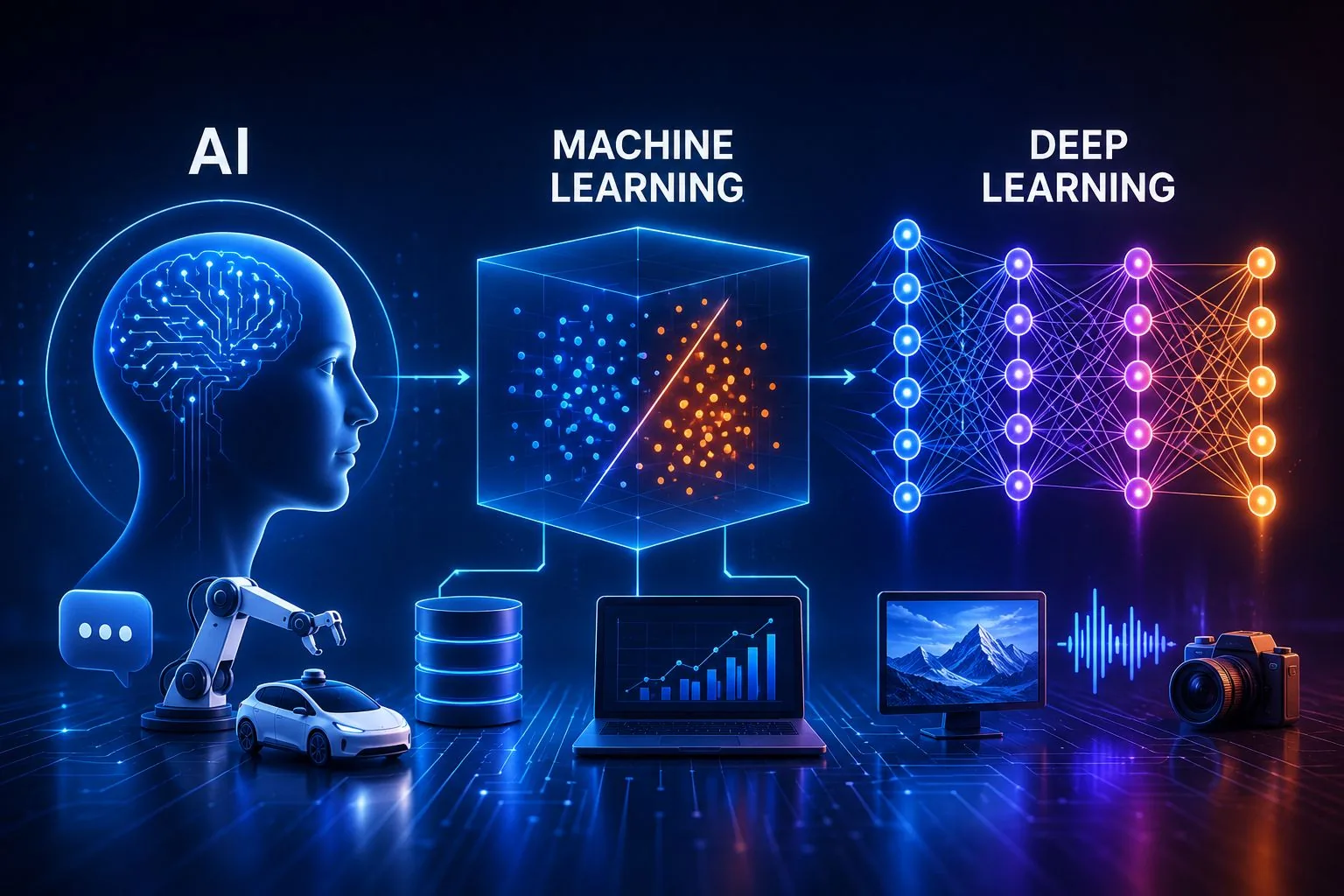
많은 사용자와 전문가들이 자주 혼동하는 인공지능, 머신러닝, 딥러닝은 각각 고유한 역할과 범위를 지닌 기술군이다. 이들 용어는 밀접하게 연결되어 있지만, 그 수준과 적용 방식은 뚜렷이 구분된다. 특히 최근 생성형 인공지능의 대중화와 가상 비서, 지능형 시스템의 확산으로 인해 이 차이를 정확히 이해하는 것이 더욱 중요해졌다. 기업과 정부, 연구기관들은 막대한 자금을 투자하여 자동화와 데이터 분석, 의사결정 시스템을 고도화하고 있다.
인공지능: 가장 포괄적인 기술 개념
인공지능은 인간의 지능을 요구하는 작업을 수행할 수 있는 모든 컴퓨터 시스템을 아우르는 최상위 개념이다. 패턴 인식, 학습, 문제 해결, 의사 결정, 자연어 이해 등이 그 핵심 기능이다. 이 용어는 1956년 다트머스 회의에서 공식적으로 처음 사용되었으며, 이후 현대 인공지능 연구의 출발점으로 평가받는다. 인공지능의 궁극적 목표는 이전까지 인간만이 할 수 있었던 일들을 컴퓨터가 대신 수행하게 만드는 것이다.
인공지능의 실제 사례
- 가상 비서
- 고객 응대 챗봇
- 추천 시스템
- 자동 번역기
- 얼굴 인식
- 자율 주행 자동차
- 콘텐츠 생성 도구
머신러닝: 데이터 기반 학습의 핵심
머신러닝은 인공지능의 하위 분야로, 모든 규칙을 사전에 프로그래밍하지 않고 시스템이 데이터로부터 패턴을 스스로 학습하도록 한다. 이 접근법은 알고리즘이 시간이 지남에 따라 성능을 개선할 수 있게 해 기술 혁신을 가져왔다. 스탠포드 대학 연구진에 따르면, 머신러닝은 예측과 데이터 분류 같은 복잡한 문제를 해결하는 주요 방법론으로 자리 잡았다. 훈련 데이터가 많고 질이 높을수록 모델의 정확도는 향상되는 경향이 있다.
머신러닝 작동 방식과 사례
- 데이터 수집
- 정보 전처리
- 모델 훈련
- 성능 테스트
- 실제 환경 적용
머신러닝은 다양한 일상 기술에 적용된다. 스팸 메일 필터, 기상 예보, 금융 사기 탐지, 영화 및 음악 추천, 컴퓨터 기반 의료 진단, 소비자 행동 분석 등이 대표적이다. 이러한 예들은 머신러닝이 얼마나 폭넓게 활용되고 있는지 보여준다.
딥러닝: 심층 신경망의 혁명
딥러닝은 머신러닝에서 진화한 기술로, 인간 뇌의 뉴런에서 영감을 받은 깊은 인공 신경망을 사용한다. 전통적인 머신러닝 모델과 달리, 딥러닝 시스템은 데이터 내의 복잡한 특성을 자동으로 식별할 수 있다. '딥(Deep)'이라는 용어는 현대 신경망의 여러 계층을 가리키며, 각 계층은 정보의 서로 다른 측면을 분석한다. 데이터가 계층을 통과할수록 더욱 정교한 패턴이 인식되며, 이미지, 음성, 자연어 처리 같은 매우 난해한 문제들을 해결할 수 있다.
딥러닝의 주요 응용 분야
- 고급 얼굴 인식
- 자율 주행 차량
- 의료 영상 분석
- 지능형 음성 비서
- 실시간 자동 번역
- 텍스트 생성형 인공지능
- 인공지능 이미지 생성
세 개념의 위계와 비교
이 세 개념의 관계는 동심원 구조로 이해할 수 있다. 인공지능이 가장 큰 원이고, 그 안에 머신러닝이 위치하며, 머신러닝 안에 딥러닝이 자리한다. 정리하면, 모든 딥러닝은 머신러닝이지만 그 역은 성립하지 않으며, 모든 머신러닝은 인공지능에 속하지만 모든 인공지능이 머신러닝을 사용하는 것은 아니다. 아래 표는 각 기술의 주요 특성을 비교한다.
| 특성 | 인공지능 | 머신러닝 | 딥러닝 |
|---|---|---|---|
| 범위 | 광범위 | 중간 | 전문화 |
| 데이터 필요량 | 낮음~중간 | 높음 | 매우 높음 |
| 연산 능력 | 중간 | 높음 | 매우 높음 |
| 이미지 인식 | 제한적 | 좋음 | 탁월 |
| 언어 처리 | 기초 | 좋음 | 고급 |
기술 성장의 동인과 변화
최근 인공지능의 급속한 발전은 세 가지 주요 요인에 의해 추진되었다. 첫째, 인간이 매일 생산하는 엄청난 양의 데이터로, 소셜 미디어와 모바일 기기, 센서, 기업 시스템에서 지속적으로 생성된다. 둘째, NVIDIA, AMD, Intel 같은 기업들이 개발한 고효율 프로세서는 고급 모델 훈련을 가능하게 했다. 셋째, 연구자들이 더 효율적인 신경망 구조와 정확한 학습 알고리즘을 창출하면서 과학적 진보가 가속화되었다.
생성형 인공지능과 노동 시장
생성형 인공지능은 딥러닝을 활용해 원본 콘텐츠를 만드는 새로운 범주로 주목받고 있다. 현재 텍스트, 이미지, 비디오, 음악, 컴퓨터 프로그램까지 생성할 수 있으며, 이는 경제 전반에 걸쳐 산업을 변화시키고 있다. 지능형 자동화는 다양한 직업을 변화시키는 동시에 데이터 과학, 인공지능 공학, 머신러닝 공학, 사이버 보안, 데이터 분석, 로봇공학, 산업 자동화 같은 분야에서 새로운 기회를 창출하고 있다. 전문가들은 인공지능 지식을 갖춘 인력이 향후 10년간 가장 가치 있는 인재가 될 것이라고 전망한다.
도전과제와 규제 움직임
눈부신 발전에도 불구하고 데이터 프라이버시, 알고리즘 편향, 에너지 소비, 디지털 보안, 자동화된 결정의 투명성, 국제 규제 등 중요한 과제가 남아 있다. OECD와 유네스코 같은 국제 기구들은 책임 있는 인공지능 개발을 위한 글로벌 지침을 논의 중이다. 미래에는 맞춤 의학, 적응형 교육, 과학 연구, 기업 자동화, 지속 가능성 분야에서 더 큰 진전이 예상된다. 인공지능, 머신러닝, 딥러닝의 결합은 사람과 조직이 일하고 배우고 소통하는 방식을 근본적으로 재정의할 것이다.