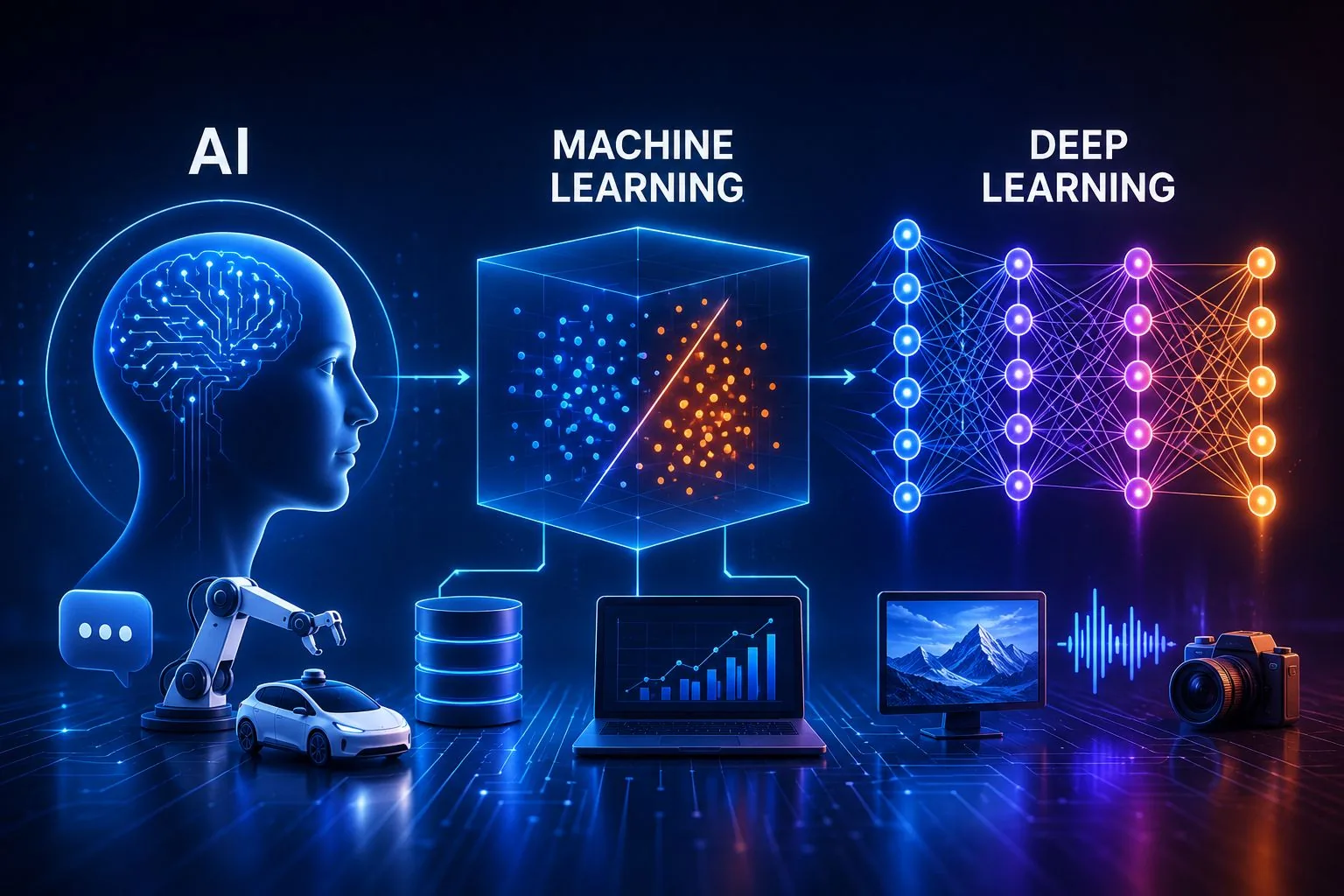
कृत्रिम बुद्धिमत्ता, मशीन लर्निंग और डीप लर्निंग – ये तीन शब्द अक्सर एक-दूसरे के पर्याय के रूप में उपयोग किए जाते हैं, लेकिन इनके बीच मूलभूत अंतर है। जहां कृत्रिम बुद्धिमत्ता (AI) सबसे व्यापक अवधारणा है, वहीं मशीन लर्निंग (ML) इसकी एक उपशाखा है और डीप लर्निंग (DL) ML का ही एक उन्नत रूप है। दुनिया भर की कंपनियां, सरकारें और संगठन अरबों डॉलर का निवेश कर रहे हैं ऐसे समाधानों में जो कार्यों को स्वचालित कर सकें, डेटा के विशाल भंडार का विश्लेषण कर सकें और बुद्धिमान निर्णय ले सकें। इन तकनीकों की बढ़ती लोकप्रियता के बीच, इनके बीच के अंतर को समझना पेशेवरों, छात्रों और डिजिटल भविष्य में रुचि रखने वाले हर व्यक्ति के लिए आवश्यक हो गया है।
कृत्रिम बुद्धिमत्ता: वह बड़ा चित्र
कृत्रिम बुद्धिमत्ता वह व्यापक क्षेत्र है जिसमें कोई भी कंप्यूटर सिस्टम शामिल है जो मानव बुद्धि की आवश्यकता वाले कार्यों को कर सकता है। इनमें पैटर्न पहचान, सीखना, समस्या-समाधान, निर्णय लेना और प्राकृतिक भाषा समझना शामिल है। इस शब्द का औपचारिक परिचय डार्टमाउथ सम्मेलन में 1956 में हुआ, जिसे आधुनिक AI अनुसंधान का शुरुआती बिंदु माना जाता है। तब से वैज्ञानिक ऐसी मशीनें बनाने के तरीके विकसित कर रहे हैं जो बुद्धिमान व्यवहार को दोहरा सकें।
कृत्रिम बुद्धिमत्ता के प्रमुख उदाहरण
- वर्चुअल असिस्टेंट
- ग्राहक सेवा चैटबॉट
- अनुशंसा प्रणाली
- स्वचालित अनुवादक
- चेहरा पहचान प्रणाली
- स्वायत्त कारें
- सामग्री निर्माण उपकरण
संक्षेप में, कृत्रिम बुद्धिमत्ता का लक्ष्य कंप्यूटर को ऐसे कार्य करने में सक्षम बनाना है जो पहले केवल मनुष्यों पर निर्भर थे।
मशीन लर्निंग: डेटा से सीखने की प्रक्रिया
मशीन लर्निंग, कृत्रिम बुद्धिमत्ता की एक उपशाखा है, जिसमें डेवलपर्स सभी नियमों को मैन्युअल रूप से प्रोग्राम करने के बजाय सिस्टम को डेटा से पैटर्न सीखने की अनुमति देते हैं। इस अवधारणा ने प्रौद्योगिकी में क्रांति ला दी क्योंकि इसने ऐसे एल्गोरिदम बनाने में सक्षम बनाया जो समय के साथ अपने प्रदर्शन में सुधार कर सकते हैं। Stanford University के शोधकर्ताओं के अनुसार, मशीन लर्निंग पूर्वानुमान और डेटा वर्गीकरण से जुड़ी जटिल समस्याओं को हल करने के लिए प्रमुख पद्धति बन गया है।
मशीन लर्निंग की कार्यप्रणाली
- डेटा का संग्रहण
- सूचना की तैयारी
- मॉडल का प्रशिक्षण
- प्रदर्शन का परीक्षण
- वास्तविक परिदृश्यों में अनुप्रयोग
प्रशिक्षण के दौरान एल्गोरिदम पैटर्न की पहचान करता है और पूर्वानुमान लगाना सीखता है। डेटा की गुणवत्ता और मात्रा जितनी अधिक होगी, मॉडल की सटीकता उतनी ही बेहतर होने की संभावना है।
मशीन लर्निंग के व्यावहारिक उपयोग
- ईमेल में स्पैम फिल्टर
- मौसम का पूर्वानुमान
- बैंकिंग धोखाधड़ी का पता लगाना
- फिल्म और संगीत अनुशंसाएं
- कंप्यूटर-सहायता प्राप्त चिकित्सा निदान
- उपभोक्ता व्यवहार विश्लेषण
डीप लर्निंग: गहरी तंत्रिका नेटवर्क की शक्ति
डीप लर्निंग, मशीन लर्निंग का एक उन्नत रूप है जो गहरे कृत्रिम तंत्रिका नेटवर्क का उपयोग करता है। ये नेटवर्क मानव मस्तिष्क के न्यूरॉन्स के काम करने के तरीके से प्रेरित हैं। पारंपरिक मशीन लर्निंग मॉडल के विपरीत, डीप लर्निंग सिस्टम डेटा में जटिल विशेषताओं को स्वचालित रूप से पहचान सकते हैं। यह छवियों, आवाज और प्राकृतिक भाषा से जुड़ी अत्यंत कठिन समस्याओं को हल करने में सक्षम बनाता है। 'डीप' शब्द आधुनिक तंत्रिका नेटवर्क में मौजूद कई परतों को संदर्भित करता है, जहां प्रत्येक परत सूचना के विभिन्न पहलुओं का विश्लेषण करती है और डेटा के गुजरने पर अधिक परिष्कृत पैटर्न की पहचान होती है।
डीप लर्निंग के अनुप्रयोग
- उन्नत चेहरा पहचान
- स्वायत्त वाहन
- चिकित्सा परीक्षणों का विश्लेषण
- बुद्धिमान वॉइस असिस्टेंट
- रीयल-टाइम स्वचालित अनुवाद
- पाठ निर्माण के लिए जनरेटिव AI
- कृत्रिम बुद्धिमत्ता द्वारा छवि निर्माण
तीनों तकनीकों के बीच संबंध
इन अवधारणाओं को समझने का एक सरल तरीका संकेंद्रित वृत्तों की कल्पना करना है। कृत्रिम बुद्धिमत्ता सबसे बड़ा वृत्त है, जिसके अंदर मशीन लर्निंग स्थित है, और मशीन लर्निंग के अंदर डीप लर्निंग आता है। इस प्रकार:
- हर डीप लर्निंग, मशीन लर्निंग है।
- हर मशीन लर्निंग, कृत्रिम बुद्धिमत्ता का हिस्सा है।
- हर कृत्रिम बुद्धिमत्ता मशीन लर्निंग का उपयोग नहीं करती।
- हर मशीन लर्निंग डीप लर्निंग का उपयोग नहीं करती।
| विशेषता | AI | मशीन लर्निंग | डीप लर्निंग |
|---|---|---|---|
| दायरा | व्यापक | मध्यवर्ती | विशेषज्ञ |
| डेटा की आवश्यकता | कम से मध्यम | उच्च | बहुत उच्च |
| कंप्यूटिंग शक्ति | मध्यम | उच्च | बहुत उच्च |
| छवि पहचान | सीमित | अच्छा | उत्कृष्ट |
| भाषा प्रसंस्करण | बुनियादी | अच्छा | उन्नत |
तीव्र विकास के पीछे के कारण
इन तकनीकों के हालिया विकास को तीन प्रमुख कारकों ने गति दी है। पहला, डेटा का अभूतपूर्व विस्तार – मानवता प्रतिदिन विशाल मात्रा में जानकारी उत्पन्न करती है, सोशल मीडिया, मोबाइल उपकरणों, सेंसर और कॉर्पोरेट सिस्टम से लगातार खरबों डेटा बिंदु उत्पन्न होते हैं। दूसरा, अधिक शक्तिशाली कंप्यूटिंग – NVIDIA, AMD और Intel जैसी कंपनियों ने उन्नत मॉडलों के प्रशिक्षण के लिए अत्यधिक कुशल प्रोसेसर विकसित किए हैं। तीसरा, वैज्ञानिक प्रगति – शोधकर्ताओं ने अधिक कुशल तंत्रिका नेटवर्क आर्किटेक्चर और एल्गोरिदम बनाए हैं जो अत्यधिक सटीकता से सीख सकते हैं।
जनरेटिव AI का उदय और प्रभाव
हाल के वर्षों में जनरेटिव AI ने वैश्विक ध्यान आकर्षित किया है। ये सिस्टम डीप लर्निंग का उपयोग करके मूल सामग्री तैयार करते हैं। आज इनके द्वारा उत्पन्न किया जा सकता है:
- पाठ
- चित्र
- वीडियो
- संगीत
- कंप्यूटर प्रोग्राम
यह तकनीक वैश्विक अर्थव्यवस्था के पूरे क्षेत्रों को बदल रही है। इस बीच, बुद्धिमान स्वचालन कई पेशों को प्रभावित कर रहा है, लेकिन साथ ही नए अवसर भी पैदा कर रहा है। डेटा साइंस, AI इंजीनियरिंग, मशीन लर्निंग इंजीनियरिंग, साइबर सुरक्षा, डेटा विश्लेषण, रोबोटिक्स और औद्योगिक ऑटोमेशन जैसे क्षेत्रों में तेजी से वृद्धि हो रही है।
चुनौतियाँ और नियामक प्रयास
प्रभावशाली प्रगति के बावजूद, कई महत्वपूर्ण चुनौतियाँ बनी हुई हैं:
- डेटा गोपनीयता
- एल्गोरिदमिक पूर्वाग्रह
- ऊर्जा खपत
- डिजिटल सुरक्षा
- स्वचालित निर्णयों की पारदर्शिता
- अंतर्राष्ट्रीय नियमन
OECD और UNESCO जैसे संगठन कृत्रिम बुद्धिमत्ता के जिम्मेदार विकास के लिए वैश्विक दिशानिर्देशों पर चर्चा कर रहे हैं। आने वाले दशकों में वैयक्तिकृत चिकित्सा, अनुकूली शिक्षा, वैज्ञानिक अनुसंधान, व्यावसायिक स्वचालन और स्थिरता में महत्वपूर्ण सुधारों की उम्मीद है।